Ya es posible ver el contenido de los archivos extraibles. Estos incluyen cualquier tipo de archivo y el contenido pueden ser otros archivo o secciones de binarios. La secciones muchas veces contienen datos binarios sin importancia, pero en otras, hay incrustado contenido relevante como imágenes, sonidos, animaciones, cursores, texto plano y demás (principalmente en DLLs).
Aquí hay un ejemplo de un .zip que a su vez contiene otro zip. En la descripción se puede ver el formato el algoritmo que se usa en cada uno de ellos.
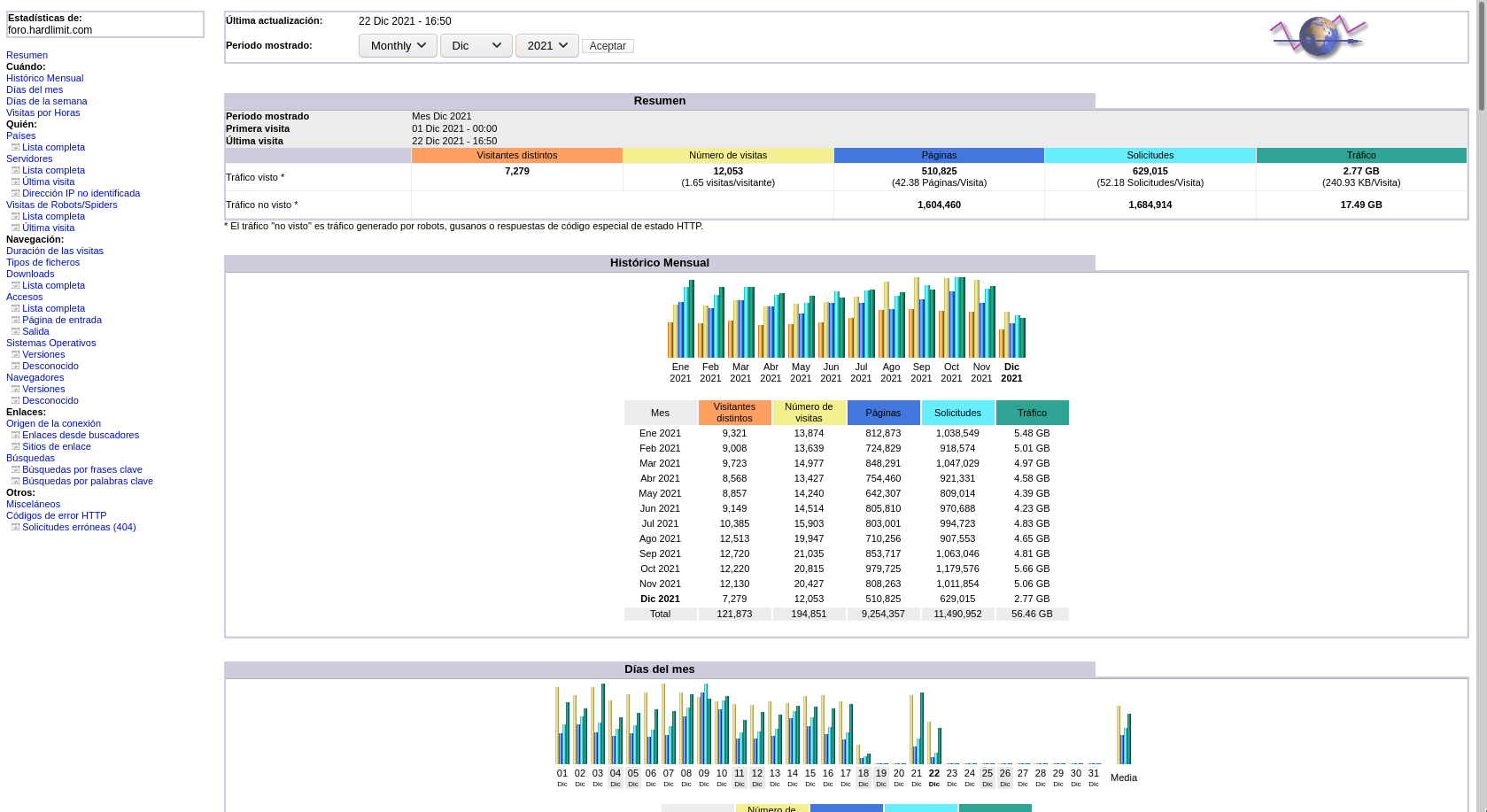
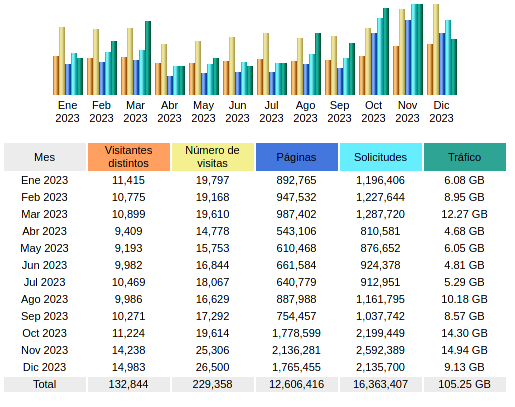
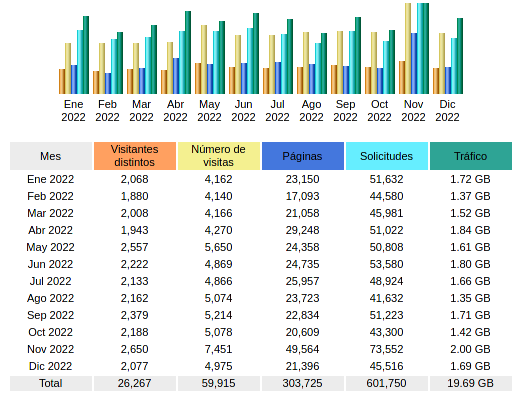
Se ha indexado el 70%. Supongo que durante el fin de semana se completará el proceso. En estos momentos, suman 1.3 millones de archivos/secciones a los que ya teníamos.
Con esto, la fase 2 en principio queda finalizada (a la espera de completar la indización, que es un proceso automático) y lo más árido del tema, queda cerrado hasta que se añadan nuevos formatos (hay ya una lista para la siguiente iteración).
Posiblemente la fase 3 comenzará próximamente, que consiste en poder visualizar los archivos desde el navegador. Esto es: imágenes, videos, sonidos, midis, mods, documentos, etc, etc, etc. Es una de las partes más chulas del explorador para la que ha sido necesario previamente hacer lo que se ha hecho hasta ahora y con lo que se puede convertir en una potente herramienta de arqueología digital.
Por otra parte, se ha consolidado el front-end en todo el museo (excepto fichas de hardware): ahora ya se usa el nuevo en todas las secciones, lo que le da un mejor aspecto en el escritorio y arregla muchas cosas que estaban rotas en la versión móvil.
Además, se han añadido los videos sobre cada hardware y software que subí en su momento a Peertube: ejemplo.
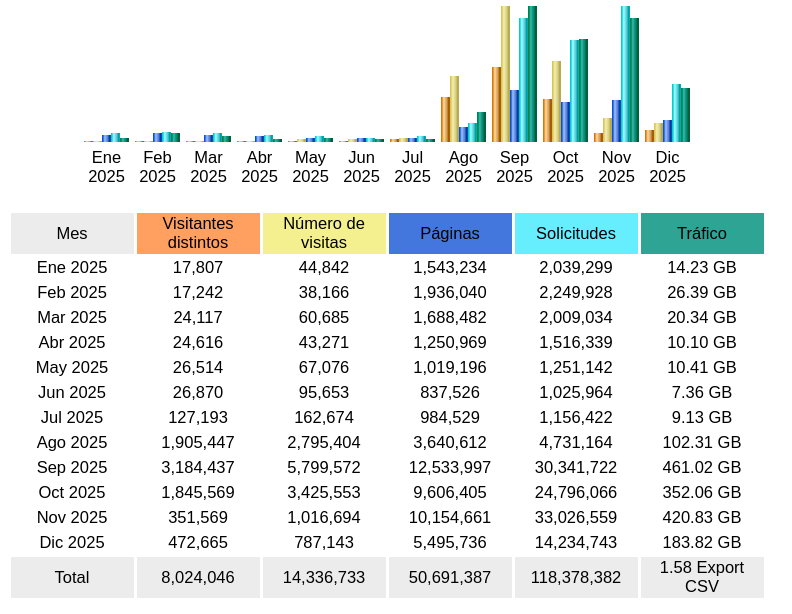

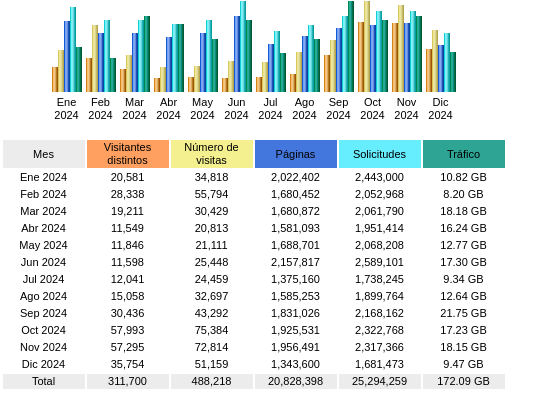


 .
.