The proof of concept for the fourth (and final) phase of the file browser is implemented. The idea here, more than adding pure functionality, was to be able to demonstrate if this was possible. And it is possible!
It consists of being able to run executables from the browser. The system automatically detects the type of executable and launches it in MS-DOS 6.22 or Windows 95/98. In addition, something else related to all this has been wanted to be tested that for the moment is limited to some formats of images and sounds: being able to visualize the files in native software. For the moment, gifs/jpegs can be seen in Internet Explorer 3/4 and BMPs in Windows 95 Paint and the three formats in Imaging. In addition,.wav can be listened to in the Windows sound recorder.
Some examples (to hear sound, you have to click on the emulation screen):
Example 0: Demo of Tomb Raider II Gold
Example 1: Demo of Theme Hospital for DOS
Example 2: Demo of Theme Hospital for Windows 95.
Example 3: Demo of International Rally Championship (- to brake, key to the right of the Ñ to accelerate, z/x to turn):
Example 4: Demo of Duken Nukem 3D (do not select sound card because they did not include the audio files and it fails)
Example 5: Demo of Epic MegaPinball.
The Windows 95 emulations also come in two flavors: with 32-bit and 8-bit color depth, so that you can experiment with palettes in images and improve compatibility in software. In this way, you have Windows 95 at 8 and 32 bits and Windows 98 SE at 32 bits, so you have several ways in case of finding incompatibilities.
Example 5: Jpeg image from Internet Explorer 3/4
Example 6: Bmp image from MS Paint
Example 7: Sound from the Windows 95 sound recorder
In the previous version of the museum, it was possible to emulate some MS-DOS programs, but there was a very strong condition: the program had to be contained in a.zip and that implied preparing individual emulations, which was extremely costly in time. Now, thanks to HLFSv2 (Hardlimit File System!), the flexibility is absolute and each file can be handled individually, wherever it is and at an amazing speed. And that without counting that it breaks the MS-DOS limit and expands, in theory, to any x86 system (there are still kilometers of fabric to cut here). With this, we have already surpassed the functionality of the previous version by far and as far as I know, we are the only ones who can run programs this way.
This topic is still green and will be polished very little by little: for example, from MS-DOS and Windows 98 it is not possible to read from cylinder 1024 of the disk (you will find read errors in very large folders: >500MB): if this happens to you with Windows 98, use 95. In addition, the virtual drive only supports files in 8.3 format and other issues.
In another order of things, from the file browser, it is already possible to search for files. Searches are in the complete file system until a specific medium/disk is visited. From there, searches are narrowed down to the medium or directory recursively. The search, unlike multimedia, orders by number of repetitions, that is, the most popular files appear first. A selection of "media" is also added in the search itself.
With this, I am already satisfied and this season of intense development of the museum closes. From now until the end of the month, changes will be consolidated and documented and there will be no major new features (beyond small fixes).
The museum, as a platform, is already defined.
Now the big thing will come from the content, regardless of the fact that there is much room for improvement in everything.
PS: The indexing of the media is 33%, so in another two weeks, practically everything will be.


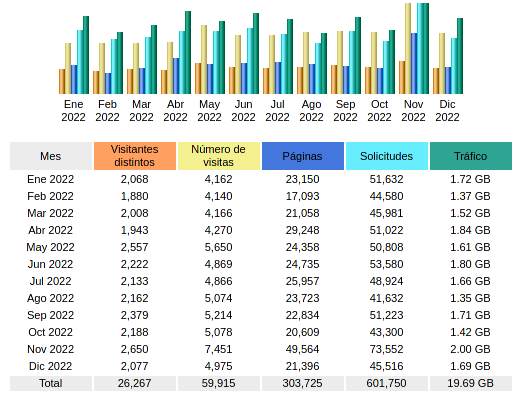

 .
.
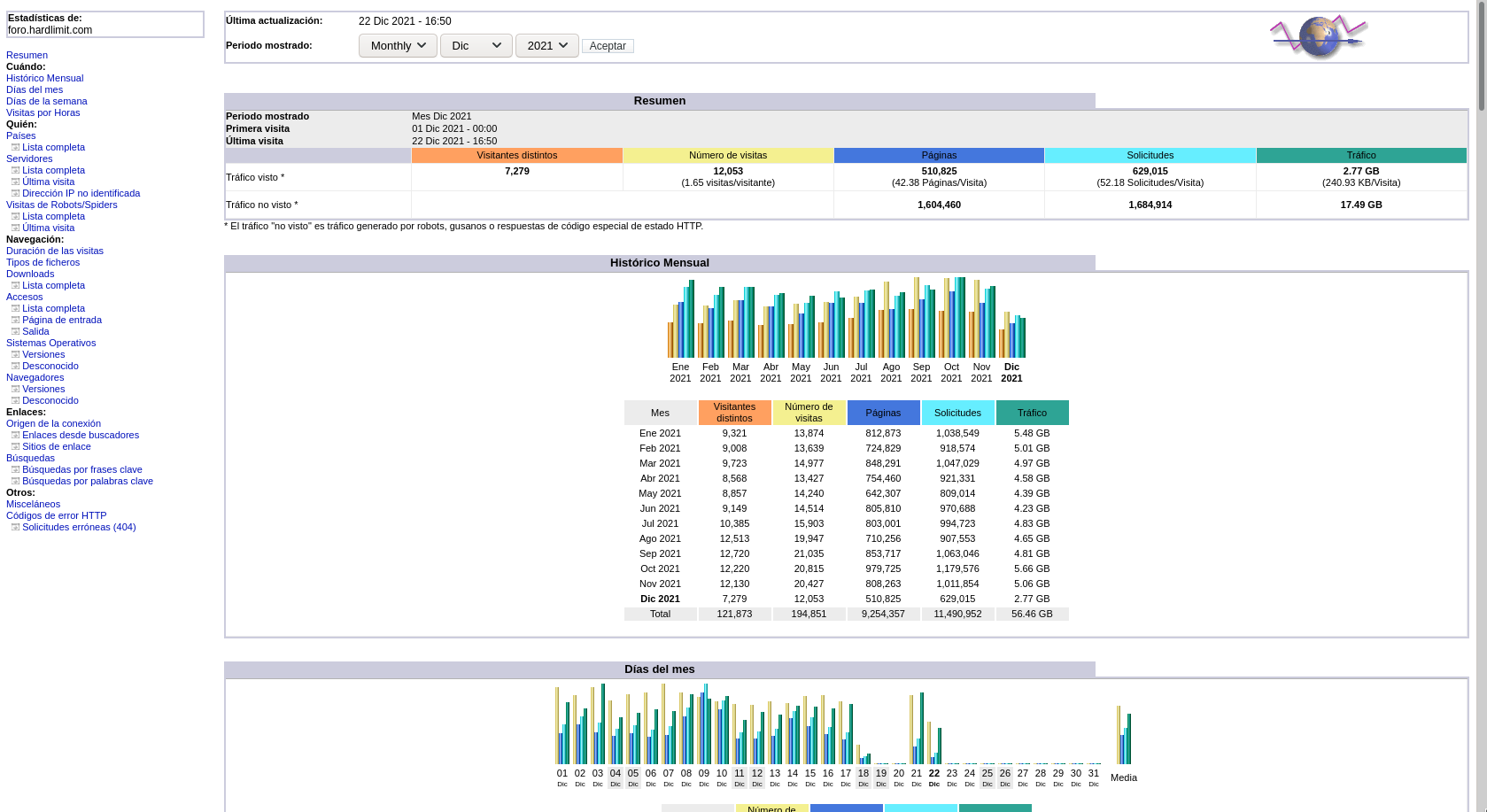
{kind=link}
{kind=link}