CPU vs. GPU
-
Este post se está procesando/traduciendo. Se muestra la versión original:
@__wwwendigo__ Entonces tenemos la misma opinión, no se que estamos discutiendo. Lo único que no he dicho es que sea algo sencillo, sino todos lo harían, pero el tema es ese que es realmente necesario que los juegos optimicen los recursos actuales. Mis opiniones creo que quedan muy claras, pero vamos si quieres que aclare más solo pregunta
")
@__fjavi__ yo la primera vez que vi lo del microstutter era con el tema de multiples gráficas, que parece que tenían problema en la división del trabajo y también se había visto que aunque mostraban por ej. 60FPS realmente en pantalla se mostraban muchas menos. Pero se ve que en ciertos juegos aun con configuraciones simples tienen reiteradamente lags a la hora de mostrar frames. Y luego están los bajones de FPS de toda la vida.
Es muy posible que con graficas de doble GPU o varias gráficas tengas problemas si no usas un buen CPU, eso no te lo niego, pero en general siempre habrá menos carga para los gráficos a menor resolución.
El tema es que mucha gente piensa que es fácil hacer uso de sistemsa multicore, y aunque sea necesario, por la parte que me toca yo comprendo los problemas y retos que se encuentran.
Es por eso que yo a la hora de recomendar cpus siempre he apostado, para usos como juegos y demás, priorizar primer el rendimiento por núcleo, y después de esto el rendimiento conjunto contando el número de cores. Los Quads llevan tiempo entre nosotros y siguen sin aprovecharse eficientemente, y no es sólo por culpa de los "ports de consolas" (XBOX 360, tres núcleos y 6 hilos, PS3, 1+6 núcleos (para la aplicación) y
2613 hilos simultáneos manejables), si fuera por esto llevarían mucho tiempo usándose bien aunque fuera con gráficos DX9. Es que el problema es peliagudo.Por eso me asombra la fe que profesa la gente con los sistemas con más cores aún, y con las nuevas consolas con cpus que tienen un rendimiento por core muy bajo (baja frecuencia, IPC normalito, con suerte) aunque tenga un buen lote para comenzar. Y por eso digo que nunca se descuide la cpu, porque no hay nada más frustante que tener una gráfica de 400€ y ver que tu cpu de 175€ aún con OC hay situaciones donde se queda un poco corta (hago ejemplo con mi caso).
Pero vamos, que no hay discusión sobre el tema. Pero ya te digo que el problema es peliagudo y de hecho más de una vez he tenido curiosidad por él pero nunca me he metido en ese tipo de berenjenales porque realmente no me "competen" (por lo menos no hasta ahora), pero la curiosidad más de una vez me llevó a investigar sobre estos temas.
En cierta forma las cpus están limitando tanto o más que la propia gráfica el diseño de juegos, porque a diferencia de las gráficas, el arco de rendimientos de cpus es más estrecho, y por tanto se pueden hacer menos "florituras" por la parte que les toca. Una de las razones para que la IA en juegos sea básicamente la misma usada en juegos de hace 10 o 15 años aún, o se tire a lo fácil de escenas scriptadas.
-
Este post se está procesando/traduciendo. Se muestra la versión original:
El futuro pasa por los multinucleo sin lugar a dudas, AMD por ejemplo está trabajando en hacer trabajar múltiples núcleos en un solo hilo, vamos al contrario del HT de Intel. Esto es tremendamente interesante, porque como sabrás en la ejecución de un juego hay cantidad de procesos con lo que teóricamente procesarlos simultáneamente podría mejorar mucho el rendimiento, claro que entretejer todo eso "manualmente" como dices es complicado, depende de los compiladores, lenguajes, programas, etc. que se usan a la hora de programar el permitir optimizar esto.
Imaginemos que podemos procesar independientemente el sistema de IA, iluminación, fisicas, cálculos de distancias, el HUD, etc. y ahora dedicar a este proceso porque consume más 4 núcleos de "potencia", a este solo uno, al otro dos, etc. Creo que eso es a lo que se aspira con la tendencia que está tomando el mundo de los procesadores.
No estoy de acuerdo con que el margen de los CPUs sea muy corto, simplemente a nivel de potencia de calculo por ciclo de reloj se ha avanzado muchísimo, aquí algunos recordamos cuando el SuperPI de 1MB se pasaba en muchos minutos y ahora tarda menos de 10". A nivel de pipeline se ha experimentado con todo, los predictores avanzaron muchisimo también, los caches y su uso compartido/independiente, sets de instrucciones, etc. los anchos de banda a memoria bus central y periféricos que ahora son prácticamente directos, etc. Es realmente impresionante la capacidad que tienen, lamentablemente resulta que para tareas cotidianas resultan igual de buenos un ARM, quizás en el futuro veamos CPUs hibridos con núcleos de diferente tipo dedicados a diferentes tipos de calculo con diferentes relojes.
Aunque el problema yo creo que es que esa potencia no les sirve de nada a los programadores porque no tienen las herramientas para explotarlo, de ahí que ahora mismo para ver la velocidad de un CPU tengas que sacar el cronometro en algoritmos como la descompresión de ZIPs o la compresión de video…
El paralelismo en si muchas veces es necesario, un CPU que pueda interconectarse con el GPU cosa que también esta en el punto de mira de AMD sería otro gran avance y logicamente necesita de usar multiples núcleos.
Y como veras aqui siempre recomendamos montar equipos equilibrados, un CPU barato con una gráfica carísima es un desperdicio. El buen rendimiento de un PC está en el equilibrio entre los componentes.
-
Este post se está procesando/traduciendo. Se muestra la versión original:
El futuro pasa por los multinucleo sin lugar a dudas, AMD por ejemplo está trabajando en hacer trabajar múltiples núcleos en un solo hilo, vamos al contrario del HT de Intel. Esto es tremendamente interesante, porque como sabrás en la ejecución de un juego hay cantidad de procesos con lo que teóricamente procesarlos simultáneamente podría mejorar mucho el rendimiento, claro que entretejer todo eso "manualmente" como dices es complicado, depende de los compiladores, lenguajes, programas, etc. que se usan a la hora de programar el permitir optimizar esto.
Imaginemos que podemos procesar independientemente el sistema de IA, iluminación, fisicas, cálculos de distancias, el HUD, etc. y ahora dedicar a este proceso porque consume más 4 núcleos de "potencia", a este solo uno, al otro dos, etc. Creo que eso es a lo que se aspira con la tendencia que está tomando el mundo de los procesadores.
No estoy de acuerdo con que el margen de los CPUs sea muy corto, simplemente a nivel de potencia de calculo por ciclo de reloj se ha avanzado muchísimo, aquí algunos recordamos cuando el SuperPI de 1MB se pasaba en muchos minutos y ahora tarda menos de 10". A nivel de pipeline se ha experimentado con todo, los predictores avanzaron muchisimo también, los caches y su uso compartido/independiente, sets de instrucciones, etc. los anchos de banda a memoria bus central y periféricos que ahora son prácticamente directos, etc. Es realmente impresionante la capacidad que tienen, lamentablemente resulta que para tareas cotidianas resultan igual de buenos un ARM, quizás en el futuro veamos CPUs hibridos con núcleos de diferente tipo dedicados a diferentes tipos de calculo con diferentes relojes.
Aunque el problema yo creo que es que esa potencia no les sirve de nada a los programadores porque no tienen las herramientas para explotarlo, de ahí que ahora mismo para ver la velocidad de un CPU tengas que sacar el cronometro en algoritmos como la descompresión de ZIPs o la compresión de video…
El paralelismo en si muchas veces es necesario, un CPU que pueda interconectarse con el GPU cosa que también esta en el punto de mira de AMD sería otro gran avance y logicamente necesita de usar multiples núcleos.
Y como veras aqui siempre recomendamos montar equipos equilibrados, un CPU barato con una gráfica carísima es un desperdicio. El buen rendimiento de un PC está en el equilibrio entre los componentes.
No sé de dónde sacas eso, pero que sepas que AMD no tiene ni un sólo producto en el mercado que haga esto, y tampoco lo hará en las siguientes generaciones a Piledriver.
De hecho eso se rumoreó mucho con Bulldozer debido a opiniones indocumentadas, antes de su lanzamiento. Dije que era un disparate, me apedrearon por decir eso (y otras cosas sobre su rendimiento) y tras el lanzamiento muchos tuvieron que pedir disculpas.
Sobre el margen de las cpus, es más escaso porque las gpus son más variables en sí, el rendimiento de hace 5 años por gpu era muy distinto al actual, y el rendimiento de una cpu de hace 5 años sin embargo no es tan distinto a las actuales. Por tanto como la potencia de cpu no cambia tanto no te puedes permitir el lujo de implementar algoritmos de IA muy avanzados, físicas equivalentes a PhysX GPU pero por cpu, etc.
Por último, aunque esto sí lo está haciendo AMD, dudo mucho que sirva para "todo", porque precisamente las gráficas están demostrando que no son buenas para muchos problemas complejos a pesar de su potencia, ya que mientras son buenas "machacando matrices" no se llevan bien con código condicional y otros usos típicos de programas también intensivos.
Esto es, AMD lo que pretende es desplazar la falta de potencia en IPC y coma flotante de sus núcleos a una gpu integrada y bien comunicada con la cpu, de forma que sea casi una extensión de la cpu más que un añadido pegado en la die pero realmente distinto.
Esto puede ser útil para acelerar alguna cosa como físicas de segundo orden (las típicas que hace PhysX GPU), cálculo matricial, incluso puede venir bien en algunas etapas del subsistema gráfico que ejecuta la propia cpu. Pero no va a servir ni remotamente para "todo", eso debería quedar claro.
Hoy en día el soft GPGPU deja mucho que desear en la mayoría de programas que están fuera del mundo científico, por multitud de razones. Y no es porque las librerías ya no estén maduras.
Lo que hace falta es mejores cores con más ipc y más frecuencia, todo esto posible pero que no se hace por la simple razón de que AMD está en aprietos e intel aprovecha para relajarse de una forma casi obscena con sus productos.
-
Este post se está procesando/traduciendo. Se muestra la versión original:
Cuando el rio suena… desde hace años se habla que era proyecto de AMD mejorar el proceso de un solo hilo en procesadores de varios núcleos, no he dicho que ya lo haya, pero por los pasos que lleva parece que por ahí van los tiros. Más que un disparate es lo lógico.
No se porque dices que no ha avanzado tanto cuando en realidad si lo han hecho, lo que pasa es que a veces nos falta memoria, y eso que no se explotan bien sus capacidades, seguro que el tiempo en idle de un CPU ha aumentado muchísimo.
El aumentar la frecuencia de los núcleos va muy atado al tamaño y tipo de fabricación, se puede mejorar el IPC aunque son realmente eficientes y tampoco se puede hacer magia con el si no hay unas instrucciones para aprovechar las capacidades. La alternativa es usar el multiproceso o mejor dicho aprovecharlo, es como el paso a 64bits, tardará años pero acabará llegando.
Intel ahora se dedica a ganar dinero, no hará grandes inversiones hasta que lo necesite, lógico. Y hasta a mi me parece bien, ahora mismo yo no me plantearía comprar un procesador con más velocidad ni con más núcleos, solo lo compraría si el IPC ha mejorado y rinde mejor porque se que del resto habrá pocas cosas que donde sacarle provecho.
-
Este post se está procesando/traduciendo. Se muestra la versión original:
Cuando el rio suena… desde hace años se habla que era proyecto de AMD mejorar el proceso de un solo hilo en procesadores de varios núcleos, no he dicho que ya lo haya, pero por los pasos que lleva parece que por ahí van los tiros. Más que un disparate es lo lógico.
No se porque dices que no ha avanzado tanto cuando en realidad si lo han hecho, lo que pasa es que a veces nos falta memoria, y eso que no se explotan bien sus capacidades, seguro que el tiempo en idle de un CPU ha aumentado muchísimo.
El aumentar la frecuencia de los núcleos va muy atado al tamaño y tipo de fabricación, se puede mejorar el IPC aunque son realmente eficientes y tampoco se puede hacer magia con el si no hay unas instrucciones para aprovechar las capacidades. La alternativa es usar el multiproceso o mejor dicho aprovecharlo, es como el paso a 64bits, tardará años pero acabará llegando.
Intel ahora se dedica a ganar dinero, no hará grandes inversiones hasta que lo necesite, lógico. Y hasta a mi me parece bien, ahora mismo yo no me plantearía comprar un procesador con más velocidad ni con más núcleos, solo lo compraría si el IPC ha mejorado y rinde mejor porque se que del resto habrá pocas cosas que donde sacarle provecho.
No, no es lógico. Hacer eso implicaría mecanismos de comunicación y sincronización entre cores en distintas de sus etapas que complicarían tanto el diseño hasta hacerlo ridículo, ya que una simple implementación de un "supercore" (fusión de recursos real de X cores) con soporte de SMT hace mejor este papel.
Ya te digo que este rumor es muy antiguo, se dijo mucho que eso era lo que haría Bulldozer (la confusión la creó la propia AMD, recuerdo alguna presentación añeja y muy ambigua), y desde que salió no volvió a hablarse en absoluto ni de lejos de algo así (por parte de AMD).
Así que seguramente no se hará, porque además de parecer un poco disparatado (ojo que no digo que imposible, sólo que yo no le veo sentido alguno), hay caminos para mejorar el IPC de verdad más directos que coger, fusionar un par de etapas en unos cores que reduces desde los K10, y después tardar varias generaciones en ¿comunicarlos? para conseguir un rendimiento… ¿poco mejor que el que tenían en origen, qué IPC podría tener algo así?
No mucho ya, un módulo de AMD de 2 cores tiene 4 decoders, eso limita el número de instrucciones por ciclo que puede ejecutar (x86), y en absoluto es mejor que lo que se puede hacer ya en otras arquitecturas que no han recurrido a esa maniobra rocambolesca.
AMD ha apostado (posiblemente mal) a simplificar cores para intentar integrar muchos en una sóla die (aunque esto no le ha salido del todo bien mirando tamaño de die y nº de transistores usados), es un buen argumento para el departamento de marketing, pero todos los problemas de rendimiento que incluso con Piledriver siguen teniendo se deben a esto.
Esta ruta iniciada con Bulldozer no acaba con ningún "SMT inverso" como el que describes. Con suerte acabarán haciendo cores relativamente rápidos y en gran número, si es que arreglan por el camino las cagadas que cometieron. Pero... fusión de cores para un mismo hilo, ni de coña:
El diseño de Steamroller en absoluto apunta en esa dirección, y lo poco que se sabe de Excavator tampoco, en principio.
-
Este post se está procesando/traduciendo. Se muestra la versión original:
Pues si el rumor data de cuando AMD comenzaba con el bulldozer, evidentemente el pipeline no puedes compartirlo pero lo que ha hecho AMD ha sido compartir el descodificador y el cache. Por desgracia no lo hicieron nada bien, porque esos dobles núcleos no eran realmente el doble de potentes en muchos aspectos como en la FPU. Y el marketing de llamar 2 núcleos a lo que realmente es 1 no le ha favorecido, pero pensándolo desde otro punto de vista lo que han hecho es coger 2 núcleos y hacer que rindan como 1 de más potencia de calculo.
Pero bueno yo cuando lo vi pese a la decepción, me quedé con la sensación que eso pero bien hecho y mejorado podría ser realmente interesante. A veces grandes ideas comienzan con mal pie, quien sabe.
A mi entender ahí está el punto en mejorar el balanceo de las cargas, a nivel de programación hay soluciones que supongo se pueden mejorar, pero si a nivel de hardware lo facilitas se podría lograr que varios núcleos funcionen como uno de mayor potencia de calculo. Logicamente como bien dices, eso no lo es todo y no puedes pretender que eso sea todo el avance, hay que seguir mejorando el IPC. Pero no podemos concebir un multi procesador como cuando Intel empezó haciendo sus "multi núcleo" pegando literalmente dos procesadores en un DIE que no compartían ni el L3 como quien dice…
PD. De Steamroller no he leido apenas, le echaré un ojo, aunque sinceramente no le tengo ninguna esperanza quizás para la escarbadora nos llevemos una sorpresa hasta entonces lo dudo.
PD2. Y no quiero decir que una operación se pueda realizar en dos núcleos a la vez que sería imposible, pero sabemos que al ejecutar varias operaciones en un hilo nunca va ser 100% eficiente a menos que sea un calculo puro y duro, el HT lo que hace es rellenar los huecos que quedan en la ejecución. Lo que yo digo es que si la cola (fetch, predictor, decoder) pudiera distribuir más eficientemente las operaciones en vez de en un FPU/ALU en varios mejoraría el rendimiento.
-
¡Esta publicación está eliminada! -
Este post se está procesando/traduciendo. Se muestra la versión original:
Pues si el rumor data de cuando AMD comenzaba con el bulldozer, evidentemente el pipeline no puedes compartirlo pero lo que ha hecho AMD ha sido compartir el descodificador y el cache. Por desgracia no lo hicieron nada bien, porque esos dobles núcleos no eran realmente el doble de potentes en muchos aspectos como en la FPU. Y el marketing de llamar 2 núcleos a lo que realmente es 1 no le ha favorecido, pero pensándolo desde otro punto de vista lo que han hecho es coger 2 núcleos y hacer que rindan como 1 de más potencia de calculo.
Pero bueno yo cuando lo vi pese a la decepción, me quedé con la sensación que eso pero bien hecho y mejorado podría ser realmente interesante. A veces grandes ideas comienzan con mal pie, quien sabe.
A mi entender ahí está el punto en mejorar el balanceo de las cargas, a nivel de programación hay soluciones que supongo se pueden mejorar, pero si a nivel de hardware lo facilitas se podría lograr que varios núcleos funcionen como uno de mayor potencia de calculo. Logicamente como bien dices, eso no lo es todo y no puedes pretender que eso sea todo el avance, hay que seguir mejorando el IPC. Pero no podemos concebir un multi procesador como cuando Intel empezó haciendo sus "multi núcleo" pegando literalmente dos procesadores en un DIE que no compartían ni el L3 como quien dice…
PD. De Steamroller no he leido apenas, le echaré un ojo, aunque sinceramente no le tengo ninguna esperanza quizás para la escarbadora nos llevemos una sorpresa hasta entonces lo dudo.
PD2. Y no quiero decir que una operación se pueda realizar en dos núcleos a la vez que sería imposible, pero sabemos que al ejecutar varias operaciones en un hilo nunca va ser 100% eficiente a menos que sea un calculo puro y duro, el HT lo que hace es rellenar los huecos que quedan en la ejecución. Lo que yo digo es que si la cola (fetch, predictor, decoder) pudiera distribuir más eficientemente las operaciones en vez de en un FPU/ALU en varios mejoraría el rendimiento.
Sobre lo primero que resalto, la culpa fue tanto de AMD por sus primeras diapositivas donde sí dió a entender que sería algo de ese estilo (lenguaje ambiguo), como de ciertos sites y gente que al más puro estilo de un Charlie Demerjian se dedicaron a lanzar la "buena nueva" de su interpretación errónea de las primeras presentaciones de AMD sobre lo que sería bulldozer.
El tema es que compartir etapas como la decodificación y la unidad de coma flotante, en realidad no tiene nada que ver con una unificación de la ejecución de un mismo hilo entre dos núcleos. Es simplemente una política de ahorro de costes compartiendo hard entre núcleos.
Estrictamente hablando son dos núcleos, porque a nivel lógico están totalmente separados sus recusos de ejecución y por no poder, ni se mezcla el código de cada hilo/proceso de cada core en la etapa de decodificación (se alternan por ciclos los decodificadores), la coma flotante separada, para el que recuerde las unidades de FPU opcionales de hace tiempo en los PCs, le sonará bastante y entenderá que en el fondo es "separar" dicho bloque de la cpu y compartirlo como un "coprocesador" entre dos núcleos, contando el que no se va a usar mucho.
Todo en Bulldozer va a la "simplificación" de cada core, supuestamente para aumentar mucho la cantidad total y "ganar" así más rendimiento total. Aunque lo hicieron condenadamente mal (que aún con Piledriver en programas masivamente multihilo lo pasen mal los Piledriver vs los Ivy i5 o i7, no es un buen indicativo, porque esta "igualdad" no se sostienen en otros programas multihilo o monohilo/ligeramente multihilo).
Lo último que dices ya te digo que es básicamente imposible, porque entre decoders y schedulers, hay todo un hard dedicado tanto a la predicción de saltos como al reordenamiento de instrucciones, con toda su ventana de registros, instrucciones, etc.
Para que un scheduler pudiera "elegir" entre dos cores distintos donde enviar las instrucciones a ejecutar del hilo/proceso, tendría que "cablearse" y añadir una cantidad de hard extra muy importante para hacer que una instrucción pueda ir de un "core" a "otro", y además lleve claramente identificado el hilo al que pertenece (y se restituya al flujo de instrucciones originario cableando también hasta el "retire", vamos una locura).
Pero eso no da ninguna ventaja, hoy en día existen a partir de los schedulers una cantidad de unidades de ejecución y posibles puertos de instrucciones que dan para conseguir un gran paralelismo, una "ALU" no es una ALU (como símil de cpu de enteros) hoy en día, es una colección de varios ALUs y unidades varias.
Lo más fácil y racional es usar este paralelismo ya enorme existente para ejecutar varios hilos en un mismo core, algo mucho más asequible para el hard actual, y que de hecho han implementando varios fabricantes (menos AMD). Se podría diseñar una cpu para que fuera por core extremadamente ancha, no ya para aprovechar el "ancho" de ejecución sobrante de la cpu para un nivel de paralelismo extraido de una cpu, sino que se podría sobredimensionar esta parte para que la ejecución de 2 o más hilos simultáneamente fueran con un rendimiento cercano al de funcionar en cores aislados.
Pero vamos, todo esto da igual, lo que dices no se puede hacer, o es poco o nada práctico. Lo que ha hecho AMD es reducir la complejidad de sus cpus "estrechándolas" en recursos de ejecución, y compartiendo etapas enteras más bloques como la FPU, en un intento de ir a una solución de "más cores es igual a más rendimiento". Lo que pasa es que hasta ahora le ha salido bastante rana la implementación.
Le habría ido mejor si se hubiera decidido a evolucionar de una vez por todas el diseño de los K10, que aunque parezca mentira es un heredero total del diseño del K7 original, en lo que respecta al balance de unidades de ejecución y decodificadores (3 decoders, 6 unidades de enteros y 3 unidades de coma flotante, una estructura mantenida desde el primer Athlon hasta el último Phenom II).
Intel lo hizo con el P-Pro remodelándolo tanto como hiciera falta, cambiando el balance de unidades, puertos de ejecución, decodificadores, etc, y bien que le ha ido.
Supuestas soluciones mágicas de "fusión de cores" sólo han surgido desde la mala prensa leyendo presentaciones confusas de AMD.
-
¡Esta publicación está eliminada! -
Este post se está procesando/traduciendo. Se muestra la versión original:
PD2. Y no quiero decir que una operación se pueda realizar en dos núcleos a la vez que sería imposible, pero sabemos que al ejecutar varias operaciones en un hilo nunca va ser 100% eficiente a menos que sea un calculo puro y duro, el HT lo que hace es rellenar los huecos que quedan en la ejecución. Lo que yo digo es que si la cola (fetch, predictor, decoder) pudiera distribuir más eficientemente las operaciones en vez de en un FPU/ALU en varios mejoraría el rendimiento.
Es que, como te comenta wwwendigo, las unidades de ejecución de un núcleo no tienen una ALU, sino varias (4 ALUs por core en Haswell, 3 ALUs por core en Sandy/Ivy/Nehalem/Core y 2 ALUs por core en los Bulldozer).
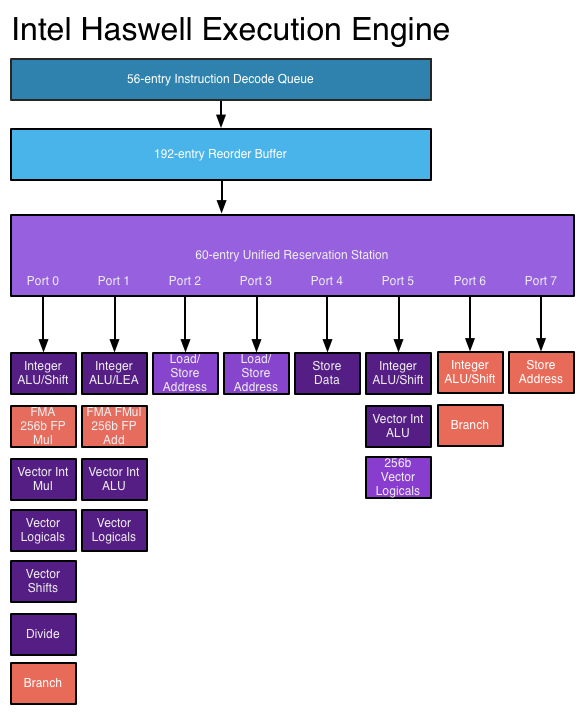
Sobre papel, en Haswell podrías enviar desde los schedulers en un ciclo 4 uops a las ALUs, es decir, estarías empleando 4 ALUs a la vez (Y ocupando los puertos 0,1,5 y 6), más las operaciones de memoria de los puertos restantes que serían otras 4 uops, es decir, 8 uops en total, una por cada puerto de los que dispone Haswelll (En Bulldozer serían 4 uops en total, 2 de computación y 2 de memoria). Por lo tanto, eso que comentas es precisamente lo que ya se hace.
Conseguir que un único hilo se ejecute en varios cores es actualmente impensable, muy complejo y con bastantes pegas.
-
Este post se está procesando/traduciendo. Se muestra la versión original:
Yo no soy ingeniero en desarrollo así que no puedo saber hasta que punto puede ser práctico o no, pero viendo la progresión es una necesidad. Y voy a explicarme mejor, un calculo no se puede partir en dos pero un hilo de ejecución ahora mismo si que se podría partir en cálculos diferentes y balancear esa carga.
Es decir si como decíamos un juego está programado en un solo hilo todo su proceso es evidente que ese hilo no consta únicamente de una sola operación sino que se puede partir y dividir. Lógicamente esto como decíamos sin las herramientas es complicado, aunque existen a nivel de software lógicamente, yo creo que la evolución en los procesadores va en mejorar el balanceo de cargas entre muchos núcleos.
También es verdad que ya hay muchas aplicaciones que crean múltiples procesos, por ejemplo en navegadores antiguamente teníamos varias ventanas pero un solo proceso ahora aun con una sola ventana abierta veremos varios procesos ejecutandose simultaneamente.
Antiguamente un servidor al ejecutar muchos procesos simplemente se repartian entre los diferentes procesadores, pero ahora mismo al tener un solo procesador que maneja varios núcleos da la oportunidad de que puedan trabajar comunicandose mucho más rapido entre sí. Es como el tema de tener el CPU y GPU compartiendo un caché, evidentemente es una ventaja.
Y simplemente yo estoy convencido de que como se ha ido mejorando para que varios nucleos trabajen mejor juntos se seguirá por ese camino. Y es que hay muy pocas tareas que requieran un solo calculo que solo pueda ejecutar un mismo núcleo, en general el paralelismo se puede explotar mucho. Y ese paralelismo es el que permitirá que un CPU pueda llegar e ejecutar unas fisicas o otras tareas que se componen de muchos cálculos paralelos.
-
Este post se está procesando/traduciendo. Se muestra la versión original:
@__wwwendigo__ Entonces tenemos la misma opinión, no se que estamos discutiendo. Lo único que no he dicho es que sea algo sencillo, sino todos lo harían, pero el tema es ese que es realmente necesario que los juegos optimicen los recursos actuales. Mis opiniones creo que quedan muy claras, pero vamos si quieres que aclare más solo pregunta
@__fjavi__ yo la primera vez que vi lo del microstutter era con el tema de multiples gráficas, que parece que tenían problema en la división del trabajo y también se había visto que aunque mostraban por ej. 60FPS realmente en pantalla se mostraban muchas menos. Pero se ve que en ciertos juegos aun con configuraciones simples tienen reiteradamente lags a la hora de mostrar frames. Y luego están los bajones de FPS de toda la vida.
Es muy posible que con graficas de doble GPU o varias gráficas tengas problemas si no usas un buen CPU, eso no te lo niego, pero en general siempre habrá menos carga para los gráficos a menor resolución.
Si el MS se da mas con SLi o CF pero también se da algún caso con monogpu,suele ser donde el CPU es mas importante por ejemplo yo he visto con una 9800GTx pero muy oceada en 3dmark06,era por que lo pasa a baja resulucion y es un test muy dependiente de CPU,tambien es verdad que las monogpu piden menos equipo que un SLi o CF o una dual,pero también influye la potencia de la monogpu.
Yo se que un SB no tiene casi nada que envidiar ni a un SB-E ni a un Ivy y menos en monogpu, pero si se junta un procesador que no se puede subir y una resolución tan baja, podria tener algún problema con algún juego, sobretodo los que sean muy dependientes de CPU.
-
Este post se está procesando/traduciendo. Se muestra la versión original:
@__Wargreymon__ no estoy hablando de nada que no exista, simplemente que con el tiempo se explotará mejor lo que ya hay, la mejor formula quien sabe. Pero estoy seguro que a corto plazo (5 años) seguiremos añadiendo núcleos porque la mejora de potencia bruta por ciclo va a seguir avanzando como siempre. Incluso parece a veces más rentable tener varios núcleos más simples o con menos ALU/FPU que uno con muchas, sobre todo para tareas simples, a quien el importa que te tarde 1" menos en descomprimir un ZIP si el procesador te cuesta un 50% más (por exagerar el tema).
@__fjavi__ a mi me llamo la atención aquel enlace que puse de un tio que con el skyrim?, al asociar el juego a un solo núcleo le bajo muchisimo el m.s. con una 7950 y un 2500.
-
Este post se está procesando/traduciendo. Se muestra la versión original:
@__Wargreymon__ no estoy hablando de nada que no exista, simplemente que con el tiempo se explotará mejor lo que ya hay, la mejor formula quien sabe. Pero estoy seguro que a corto plazo (5 años) seguiremos añadiendo núcleos porque la mejora de potencia bruta por ciclo va a seguir avanzando como siempre. Incluso parece a veces más rentable tener varios núcleos más simples o con menos ALU/FPU que uno con muchas, sobre todo para tareas simples, a quien el importa que te tarde 1" menos en descomprimir un ZIP si el procesador te cuesta un 50% más (por exagerar el tema).
Eso está claro, llegará el día en que Intel nos saque 6/8 núcleos en el segmento performance, pero no estoy de acuerdo en que sea más rentable tener núcleos más simples pero en mayor cantidad sobre núcleos más potentes y en menor cantidad, la mejor apuesta sigue siendo el mayor rendimiento por ciclo posible, y después de eso ya el número de núcleos (Salvo que hablemos de diferencias muy pequeñas en cuanto a ipc entre una CPU de 2 núcleos y otra de 4 claro).
Lo que hace el CryEngine 3 en el Crysis 3 con la CPU por ejemplo es muy interesante por que parece ser capaz de emplear todos los hilos que tenga una CPU (Creo que el tope son 12 hilos) para evitar cosas como las que ocurren en el Tomb Raider o en el crysis original que también tenía (Y tiene) ese problema de dependencia de CPU siendo capaz de usar pocos núcleos, así que acaba saturandolos y limitan el rendimiento.
-
Este post se está procesando/traduciendo. Se muestra la versión original:
Parece que será AMD quien acabe sacando más núcleos, a Intel aun no le hace falta :troll:
Un buen ejemplo son los ARM que no me estañaría que acabasen saltando al mundo de los portátiles, los X86 actuales son bastante complicados e innecesarios para muchas tareas ligeras, lo ideal es un buen equilibrio entre IPC y paralelismo. Con un soft bien preparado sería como pensar hoy en comprar un mono núcleo sin HT, por muy potente que sea, no sería una buena idea.
-
Este post se está procesando/traduciendo. Se muestra la versión original:
Parece que será AMD quien acabe sacando más núcleos, a Intel aun no le hace falta :troll:
Un buen ejemplo son los ARM que no me estañaría que acabasen saltando al mundo de los portátiles, los X86 actuales son bastante complicados e innecesarios para muchas tareas ligeras, lo ideal es un buen equilibrio entre IPC y paralelismo. Con un soft bien preparado sería como pensar hoy en comprar un mono núcleo sin HT, por muy potente que sea, no sería una buena idea.
¿ARM más fácil que x86?, si existe desde los años 70, arquitectura más conocida y familiar que esta dificil…
De poco sirve que las CPUs de AMD tengan más núcleos si incluso con todos en uso, como mucho, igualan a un i7 de la competencia, y con pocos hilos directamente la competencia los humilla.
Sinceramente, me extrañaría bastante que AMD sacara CPUs con más de 8 núcleos a corto plazo, sacar un Bulldozer con 10 o 12 núcleos no les iba a servir para nada más que hacer chips más caros y con el mismo rendimiento. Viendo los cambios que están haciendo en steamroller, que afortunadamente son cambios hacia adelante salvo fracaso de última hora, más bien se están centrando en tratar las debilidades de la arquitectura en lugar de en mantenerla y seguir metiendo núcleos a lo bestia.
-
Este post se está procesando/traduciendo. Se muestra la versión original:
ARM es una arquitectura más simple y el x86 de hoy en poco se parece al de hace 40 años. Poner o quitar núcleos no tiene ningún gasto de I+D es mas o menos gratuito; si no puedes vender uno de 4 núcleos porque tiene muy bajo rendimiento vende uno de 8 y más barato, es lo que llevan haciendo bastante tiempo. E Intel no saca procesadores de 8 núcleos porque "no quiere", no le interesa explotar el mercado aun.
-
Este post se está procesando/traduciendo. Se muestra la versión original:
Hace tiempo se rumoreaba sobre la presencia de procesadores ARM en las futuras gráficas de AMD :sisi:
Si no lo hacen ellos mísmos, no descarteis que algún fabricante como TUL (PowerColor) lo haga.
Salu2!
Intel i5 3570k / ASRock Z77 Extreme 4 / G.Skill F3-12800CL9D-8GBRL / Sapphire HD5850 / Samsung HD103UJ / TR TrueSpirit / NZXT Source 210 / OCZ ZS550W
Intel i5 4570 / ASRock H87 Pro 4 / 2x G.Skill F3-14900CL8-4GBXM / Samsung 850 EVO 250Gb + ST1000DM003 + ST2000DM003 + HGST HDS723020BLA642 + Maxtor 6V250F0 / CM Seidon 240M / Zalman MS800 / CM MWE 550
AMD Ryzen 7 1800X / B350 / 2x8GB Samsung DDR4-2400 CL17 / NVIDIA GTX 1070 8GB / SSD 120GB + ST4000DM004 + ST6000DM003 / EVGA Supernova 650 G2 -
Este post se está procesando/traduciendo. Se muestra la versión original:
ARM es una arquitectura más simple y el x86 de hoy en poco se parece al de hace 40 años. Poner o quitar núcleos no tiene ningún gasto de I+D es mas o menos gratuito; si no puedes vender uno de 4 núcleos porque tiene muy bajo rendimiento vende uno de 8 y más barato, es lo que llevan haciendo bastante tiempo. E Intel no saca procesadores de 8 núcleos porque "no quiere", no le interesa explotar el mercado aun.
Lo dices como si supusiera alguna "ventaja" el salto a ARM, y te voy a decir una cosa, arquitecturas RISC de primerísima calidad han caído ante x86 no sólo por razones de coste, sino también de rendimiento. Ni tampoco ARM es el mejor ejemplo de arquitectura "RISC simple", porque no lo es. Por no tener ni tiene un tamaño de instrucción fijo y estable, como sí lo tienen otras arquitecturas RISC más prototípicas (precisamente ARM imita en ciertos aspectos las cpus CISC por temas de consumo de memoria).
El 99% de los programadores lo hacen o con lenguajes de alto nivel o como mucho en C, por lo que realmente les da igual casi la arquitectura que tenga por debajo la cpu. Y si programas algo en ensamblador, sólo son secciones limitadas de código, normalmente para realizar bucles de cálculos intensivos, que te da igual hacerlos con una que con otra arquitectura.
La calidad de los compiladores x86 no tiene equivalente en otras arquitecturas, tras tantos años y gente trabajando en esto, no hay ni una sóla razón para preferir ARM o cualquier otra cpu RISC por la mayor "bondad" (que no) de arquitecturas no x86 (fuera de la orientación hacia el consumo de ARM).
Al único que le insteresaría no usar x86 sería quizás a programadores de sistemas operativos y similares, que ya tienen que bregar con más problemas de la arquitectura. Y aún así, con peros.
Sobre 4 u 8 cores y la "conveniencia" de la última senda, los dos ejemplares que se han citado:
Piledriver 8C: 315 mm2 de die y 1,2 mil millones de transistores (32nm).
Ivy Bridge 4C: 160 mm2 de die y 1,4 mil millones de transistores (22 nm).
Sandy Bridge 4C: 210 mm2 de die y 1,16 mil millones de transistores (32 nm).He puesto los dos últimos intel porque uno está fabricado en 22 nm, y para poner como contraste una cpu que no sólo es competitiva igualmente contra Piledriver (más que eso, realmente), sino que está fabricado en un nodo de fabricación "similar".
AMD sólo en soft multihilo masivo, que no use demasiado la coma flotante, consigue igualar los resultados de los dos intel aquí colocados, pero eso sí, a costa también de consumos y frecuencias más altas para lograrlo (así que estrictamente hablando, no consigue ni con el número de cores compensar su bajo IPC, necesita además frecuencia extra contra los intel).
Fuera del soft masivamente multihilo mencionado, que se adapta bien a este tipo de cpu, el rendimiento de Piledriver es de mediocre a malo comparativamente hablando.
Ahora, ¿ha conseguido AMD duplicando cores mejorar el rendimiento máximo de x86? NO, todo lo contrario, tiene que recurrir a disparar su TDP y frecuencias para igualar la balanza.
¿Ha conseguido AMD implementar más cores por tamaño de die que su rival intel? Tampoco, además del impresionante tamaño del Piledriver (más de 300mm2, como una gpu de gama media-alta actual, bastante lejos de lo típico en cpus de gama media), hay que tener en cuenta otros factores:
En AMD te venden sólo la cpu con Piledriver, intel vende en la misma pastilla su gpu, que por lo menos en Ivy ocupa más de 1/3 de la die final, y algo menos en Sandy (¿1/4?), si a intel le diera por ahí en ese mismo espacio que ocupa la gpu podría agregar un par de cores extra más la expansión de la L3 consecuente. Casi lo mismo o con poco o nulo crecimiento del área necesaria en Sandy.
Sandy sin GPU con sus 4 cores ocuparía más o menos 150 mm2, con lo cual AMD con toda esa cirugía "reductora" de capacidades de cada uno de sus cores, compartiendo recursos, teniendo que meter cachés enormes para compensar errores de diseño (el mismo tipo de cachés en sí), y otros dimes y diretes, no habría conseguido realmente reducir el consumo de área por core respecto a su rival con su arquitectura "bulldozer".
Esto es, ofrece un mucho peor IPC, necesita meter 8 cores para rivalizar con un 4 cores en soft multihilo, gasta una die que duplica el gasto en cores del rival, y dado que aún así no le llega con su diseño para vencer al rival necesita compensar subiendo frecuencias y consumos.
Lo que la mayoría de la gente NO sabe sobre Bulldozer y derivados es que se supone que es un cpu "Speed Demon", una cpu cuyo diseño se simplifica y de hecho se vuelve menos eficiente apostando por cambios que le permitiría alcanzar frecuencias de reloj mucho más altas. Bulldozer tenía que salir a unos 5 GHz o así se esperaba inicialmente, para compensar y ofrecer un "plus" respecto al rival. O sea, que esta cpu tendría que poder funcionar con OC con rangos de 6 GHz con relativa facilidad y por aire.
Pero AMD se ha metido exactamente el mismo batacazo que se dió intel con el Pentium4 cuando "descubrió" (algo ya sabría, detrás del p4 yo ví mucho dpto. de marketing satisfecho con números de frecuencia) que a pesar de que el diseño puede subir de frecuencias, no lo hace sin disparar los consumos y sin volverse en impracticable para montar en PCs ordinarios (con como mucho RL como método de disipación).
Lo cual es especialmente penoso teniendo como tenía el ejemplo en el rival de qué no hacer. Pero nada, a simplificar, empaquetar muchos cores ineficientes, y meter mucha frecuencia para compensar sus errores de diseño.
Los únicos contentos serían otra vez los chicos de marketing que pueden "presumir" en sus folletos de 8 cores y de más de 4 GHz, la publicidad cojonuda para promocionar al más puro estilo Mediamarkt, "yo no soy tonto".
MORALEJA:
Si quieres una buena cpu generalista apuesta por un equilibrio, no vayas a por apuestas sin sentido de un fabricante que parece haber tomado esa mala decisión sólo porque no se veía capaz de responder con Phenom a arquitecturas tan como Core. La mala decisión de intel con el P4 también fue alimentada por su derrota en la carrera del GHz contra el Athlon usando su Pentium III.
Que cosas de la vida, resulta que es el "padre" de toda la gama actual de cpus x86 de intel (excepto Atom). Y nunca desprecies un buen IPC, porque simplemente hay tipos de soft que no se adaptan ni de broma bien a ejecución multihilo y eficiente.
Fassou:
¿Ese "rumor" no será más bien con las gráficas de nvidia? porque ahí sí está más o menos confirmado que se implementará algún sistema híbrido gpu-cpu por su parte.
-
¡Esta publicación está eliminada!
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Registrarse Conectarse