@pcgaldo es un filtro automático que a veces tiene falsos positivos. Es posible que casualmente se hayan acumulado peticiones de Mastodon y Peertube y haya saltado.
No le daría mayor importancia si no vuelve a suceder.
@pcgaldo es un filtro automático que a veces tiene falsos positivos. Es posible que casualmente se hayan acumulado peticiones de Mastodon y Peertube y haya saltado.
No le daría mayor importancia si no vuelve a suceder.
Buenas @pcgaldo. La IP asociada a ambos subdominios (la misma para los dos) había sido baneada por actividad sospechosa relacionada con rastreo agresivo.
Ya se ha eliminado de la lista de bloqueo. Si vuelve a pasar, responde por aquí y vemos a ver por qué puede estar saltando.
Anoche petó miserablemente el disco duro del Ryzen 9 9900X. Eso nos ha dejado sin foro ni traducciones todo el día. Ha sido un desastre. Llevo unas 10 horas poniendo todo a punto, lo cual ha sido buscar un disco duro funcional, instalar el sistema e intentar recuperar la base de datos del foro del disco cascado. Ha sido imposible recuperar la base de datos así que he tenido que recurrir a una copia de seguridad del sábado. Eso quiere decir que se han perdido los hilos y crossposts desde entonces.
De momento, nuestros bots (Smith y HIAL-9000) están fuera de servicio. Tengo que volver a poner en marcha toda la infraestructura IA que será lento y estará para hoy u otro día.
@jordiqui Por un fallo de hardware, se ha perdido la respuesta a este hilo donde preguntabas sobre el número de visitas desde ijccrl.com para comprobar el impacto de incluir un enlace al foro. Respondí ayer que en lo que llevamos de año, se han recibido 7 u 8 visitas como referidos, pero que debido a saqueo de bots (que además se reactivó hace 10 días después de un mes de descanso), es imposible sacar nada en claro de las estadísticas.
Venga, última chapa del curso:
Se acerca el final de trimestre y con él, el parón vacacional que este año tendrá una duración superior a la habitual.
Al final, el banco de pruebas se ha quedado a medias y va a quedar en fase beta unos meses. Quiero seguir haciéndole cosas antes de firmarlo.
Básicamente se han incorporado nuevas funcionalidades a la interfaz junto a herramientas secundarias, pero el Core queda sin modificaciones a pesar de que ha recibido muchos cambios que no se han incluído. Hay varias decisiones que tengo que tomar.
La razón de no haber sacado más novedades es que el código del programa era (y sigue siendo en cierta medida) un auténco quebradero de cabeza. Ahora está muchísimo mejor a como estaba, pero es algo que ha estado abandonado todo este tiempo a diferencia del resto de páginas, que han recibido algo de cariño en los últimos 5 años. De hecho, la mayor parte del código del Core era prácticamente el mismo desde las primeras versiones estables (¿hace 10 años?).
En resumen: se han dedicado muchas horas a trabajo no visible, pero que ha servido para acelerar a partir de ahora la publicación de novadades.
Me ha sido imposible dedicarle tiempo en los últimos días, así que probablemente no haya más betas hasta después del verano.
Ha sido la gran abandonada. Después de experimentar con el tema de los resúmenes de los videos, he visto que la IA es superior a mi entendiendo, corrigiendo y cocentrando conceptos. La portada consiste básicamente en hacer un pequeño resumen de noticias que hasta ahora he hecho manualmente. Y la verdad es que después de ver eso, me ha empezado a dar una pereza increíble seguir haciendo esa tarea. Es como tener una excavadora último modelo con el depósito lleno de combustible y apoyado sobre sus ruedas, un pico y una pala carcomidas del uso esperando a que alguien las coja para cavar una zanja. ¡Qué pereza cavar una zanja a pico y pala! La parte penosa de todo esto es que la razón de ser de la portada ha sido, entre otras cosas, hacer ver que hay personas detrás manteniendo el sitio. Y delegar el esfuerzo cognitivo de esta tarea a una máquina, va a eliminar de un plumazo ese "símbolo" de actividad. Por otra parte creo que en estos momentos no es necesario dar muestras de actividad sólo por darlas.
En general, la portada es algo que no me motiva demasiado desde hace tiempo, porque es difícil encontrar verdaderas noticias (el mundo de la informática personal está esencialmente muerto), porque el sensacionalismo está a la orden del día y porque a veces hay que contrastar informaciones inverosímiles (pero potencialmente ciertas). Es mucho tiempo y esfuerzo y el valor que aporta es discutible. Si una máquina puede hacer ese trabajo y encima lo puede hacer mejor que yo, ¿por qué no?
Todavía tengo que tomar la decisión final, pero es bastante probable que a la vuelta (en algún momento de septiembre), la portada sufra un cambio radical en sus entrañas. Es la única página que no ha recibido horas de desarrollo en el último año y ya que se va a rehacer, creo que se va a enfocar el tema de esta forma.
Estoy intentando inyectarle actividad desde la instancia de Peertube. Me parece que es el lugar adecuado para publicar contenido en formato texto y de hecho, estaba pensando en migrar las entradas de mi antiguo blog retro al foro. También estaba pensando en crear entradas sobre videos temáticos (en estos momentos me viene a la cabeza The Computer Chronicles) en un nuevo subforo retro ya que es una rama con mucho ímpetu en estos momentos.
En este aspecto, estoy todavía en terreno desconocido. Si las redes sociales y el SEO agresivo acabó con la era de los foros hace más de una década, estoy dándole vueltas a ver de qué forma encaja un foro en la actual era IA. Ofrecer contenido como punto de partida a discusiones no es complicado siempre que siga habiendo generación de contenido en la instancia de Peertube. Que sea un centro de consultas sigue siendo una posibilidad en cuestiones muy específicas y poco documentadas. Pero atraer a gente que participe de forma directa, es un reto.
Veré si rescato viejas fórmulas...
Este trimestre ha estado totalmente abandonado. Sigue siendo el centro de gravitación de mi interés porque es donde me siento más cómodo haciendo experimientos y sin miedo a que se rompan cosas. Pero no puedo dejar abandonado el resto y además, uno también se cansa de estar siempre con lo mismo.
Me apetece meterle contenido a puntapala y poner al límite todo el desarrollo que hice hace unos meses a ver cómo se comporta a gran escala, pero la falta de almacenamiento me lo impide. Aún así, tengo algunas ideas para exprimir hasta el último byte de los 2TB que tenemos asignados a este proyecto.
Tenemos tres urgencias: más almacenamiento, más capacidad de procesamiento GPU y más eficiencia energética. Son tres máquinas que, a día de hoy, cuestan una fortuna inasumible. Durante el próximo curso, la adquisición de este hardware va a depender exclusivamente de la evolución de los precios y eso nos sitúa, como poco, en 2027.
Por su parte, la vorágine acaparadora de scalpers IA se ha reducido mucho hasta el punto de que, en estos momentos, estamos a régimen nominal tanto en el uso de ancho de banda como de CPU. Y si os soy sincero, tengo verdadera curiosidad por saber las razones que hay detrás de esta caída abrupta de la actividad con respecto al momentum que vive la IA, independientemente de que esta caída sea muy beneficiosa para nosotros. Saber a dónde se dirige la informática personal en los próximos meses depende de forma directa de lo que haga la "industria" de la IA, y siendo un ámbito tan sumamente opaco, tener estas muestras discretas de información siempre ayudan un poco a entender la situación.
Para el curso que viene no tengo nada especial planificado: naturalmente, el programa del banco de pruebas será prioritario. En esencia me voy a dejar llevar un poco más por lo que me apetezca en cada momento (sin dejar nada abandonado y con cierta planificación) y en cómo de posible sea comprar el hardware planificado ya que en estos momentos estamos un poco limitados en ese aspecto.
Si puedo conseguir un rato, podría sacar algo más hasta la primera semana de julio, pero poca cosa ya.
¡Feliz verano!
Actualización rápida:
 ).
).Se ha implementado el tratamiento de los hilos federados por el traductor. Hasta ahora no era posible capturar los hilos porque Nodebb no exponía ninguna lista que incluyera estos hilos pero con la última actualización, eso ha cambiado. De esa forma, ya no veréis el molesto mensaje "Este post se está procesando/traduciendo..." indefinidamente. De momento se ha probado con algunos hilos viejos (no todos están incluidos porque estamos en modo "bajo consumo") pero se aplicará a todos los nuevos.
Por otra parte, se ha implementado una miniherramienta que necesito para gestionar los servidores y que os comparto por si os sirve: desde extra.hardlimit.com/ip obtendréis vuetra IP pública en una cadena de texto plano, sin maquetación HTML.
@wildperal@video.hardlimit.com La conversación está teniendo lugar en el foro: https://foro.hardlimit.com/es/topic/dcf369ed-a1ee-41f5-9561-8ac6f3094a00
Debido a un fallo del foro, no aparece el vídeo. Pero en Peertube se ve bien.
@krampak Los videos se muestran en https://foro.hardlimit.com/es/topic/63366/videos-peertube
En esta versión de Nodebb se anunció una nueva característica que consiste en mostrar el video empotrado en los hilos federados provenientes de Peertube. Supuestamente eso entraba en vigor con los nuevos hilos (los antiguos se quedan como están). Pero acabo de hacer una prueba y sigue sin funcionar (ahora lo reporto).
La novedad ahora es que los hilos federados sí aparecen en hilos no leídos cuando hay nuevos mensajes, lo cual les da visibilidad, por ejemplo, cuando alguien comenta.
¿Quizás debería añadir un enlace al video y otro al foro en el resumen del video para que se sepa de donde vienen las cosas en ambos lados?
La actuaciones de hoy en principio ya están.
Se ha mudado la parte web proxy al VPS. Con eso, se han estado haciendo pruebas de caché y ahora se cachea principalmente contenido de la instancias de Peertube (videos e imágenes), de la instancia de Mastodon y del museo. Se espera incrementar notablemente la velocidad de carga de ciertos archivos, principalmente de las emulaciones del museo, carga de imágenes y visualización de videos con más tráfico. Con esto también se espera reducir la actividad I/O del NAS y el resto de discos.
Desde el punto de vista de la seguridad este es un cambio radical porque aísla la máquina expuesta a Internet de todo lo demás: ya no hay contacto directo de nada con el exterior excepto el proxy-caché, que en realidad no almacena información de ningún tipo.
Sobre el software, se han hecho las siguientes actualizaciones:
Por su parte, al Ryzen 9 9900X se le ha desactivado al XMP (pasa de 6400MT/s a 4800MT/s, un 25% de reducción). Se hace para reducir las tensiones de 1.4 a 1.1V y es una cuestión puramente térmica y de durabilidad: como esas memorias casquen, tenemos un problema de los grandes. Esto va a tener un impacto directo en los modelos de IA. En estos momentos, haciendo tareas en directo (conforme van apareciendo y sin repasar cosas pasadas), todavía sobra capacidad. Cuando el calor empiece a aflojar, se volverá al esquema XMP.
@krampak Gracias por los apuntes. Tomo nota.
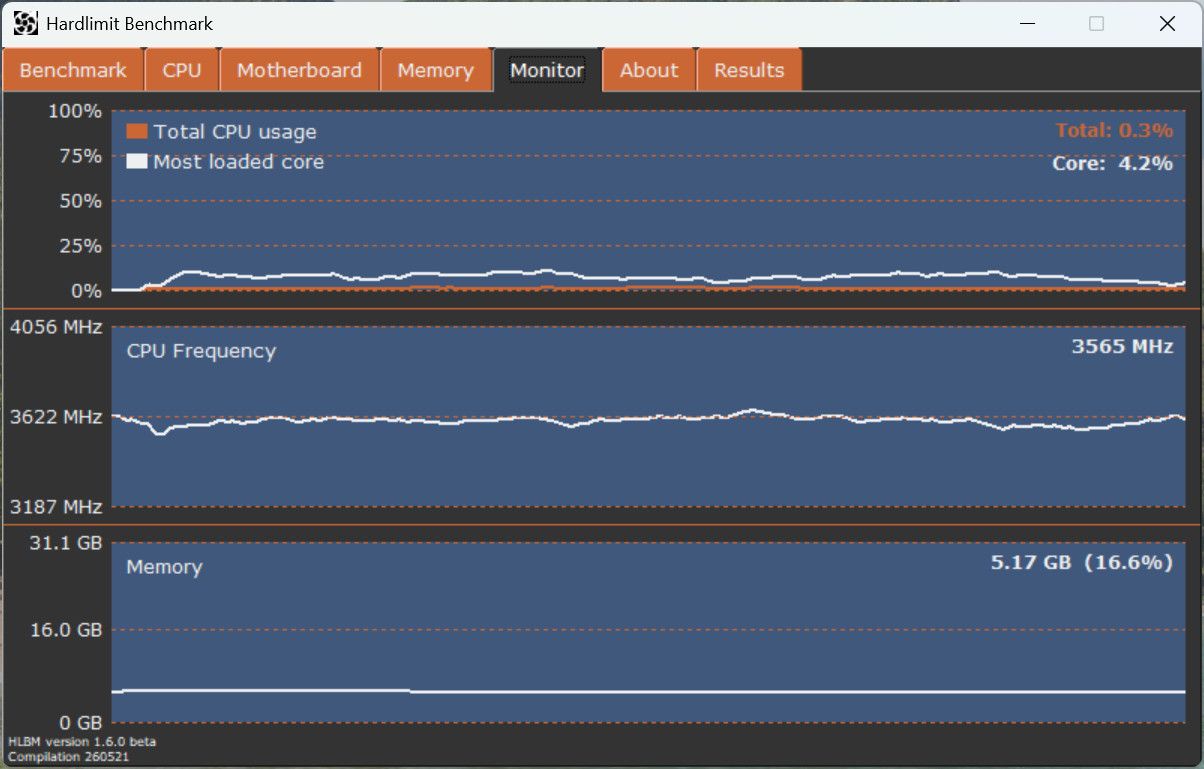
La estética la cuadraré cuando esté todo más definido. He ampliado la ventana por el Monitor, sí, pero también para mostrar más información en pestañas preexistentes. Por ejemplo, la pestaña de memoria ahora muestra hasta 8 slots de memoria que ocupan prácticamente toda la superficie cuando están presentes.
Sí, la gráfica hace cosas raras. Es por la media móvil. Las estadísticas muestran una variabilidad demasiado grande si se muestran a frecuencia de refresco y la verdad es que no sale una gráfica fácil/agradeble de interpretar. Por eso se suaviza con media móvil que es lo que falla cuando las muestras se van extinguiendo. Apuntado queda.
Se ha añadido el campo "proceso" (proceso de fabricación) donde aparece tanto el nombre comercial como el ancho de puerta en la ficha del procesador (cpu.php).
Podéis descargar esta compilación desde aquí.
Hace unas horas ha aparecido un parche de seguridad de Peertube que parchea a su vez otro fallo descubierto hace 3 días. La instancia de Hardlimit se actualizó tanto hace 3 días como hace unas horas.
La vulnerabilidad permitía hacer inyecciones de código, inyecciones SQL, instalación de plugins y explotar tokens de procesamiento para manipular los videos publicados por los usuarios. Además, han detectado una manipulación del dominio de Google Analytics que reportaba los datos de trafico a un sitio ilegítimo (esto no lo usamos nosotros).
Se han realizado las comprobaciones que se han indicado desde los desarrolladores de la plataforma y no se han detectado indicios de penetración ni manipulación.
A partir de ahora, la instancia está segura ante estos fallos pero ha habido que resetear todas las sesiones de usuario, por lo que os tendréis que loguear de nuevo.
@krampak: En cuanto al monitor de recursos, veo que va muy despacio cuando se está pasando el test pero en idle el gráfico va a toda castaña, como si el eje de tiempo transcurrido no fuera el mismo, es normal?
La idea de diseño de las gráficas es que se refresquen rápido, mucho más que en el Administrador de tareas. En estos momentos (no es la cifra final), el refresco es de 24Hz.
Es normal que vayan lentas durante la prueba porque el hlbm-core acapara todo el tiempo de CPU del hilo. Durante la prueba no deberían mostrarse las gráficas porque tienen un pequeño consumo de CPU y eso altera el resultado (quizás por eso tu puntuación ha bajado). La idea final es evitar que sea posible cambiar de pestaña durante la prueba y que aparezcan valores numéricos de consumo en la pestaña "Benchmark" con una tasa de refresco baja.
@cobito no era la primera vez que paso el test, pero sí la primera que lo registro con mi nick (al menos eso creo). El caso es que me he dado cuenta de una ligera discrepancia entre lo que dice el test en sí y lo que aparece en la página. Bueno, que conste que me da igual, simplemente lo comento por si ayuda o por si es que funciona así:
Efectivamente, hay una discrepancia de metodologías que se introdujo de forma accidental en la v.4.x.x de la central. En realidad es un fallo de la central y no del programa. Gracias por el recordatorio, porque creo que no lo tenía ni apuntado.
Gracias a todos por los comentarios y las pruebas.
Ya está disponible la primera beta de la nueva versión. Como el ejecutable está sin firmar, tenéis que desactivar el Smart App Control para poder probarlo. Ojo con esto porque si lo desactiváis globalmente en las últimas versiones de Windows 11, luego ya no se puede volver a activar sin reinstalar el sistema. No sé si se podrá poner una excepción a un ejecutable en concreto.
En esencia (y sin entrar en detalles en cambios internos), se ha añadido una nueva pestaña "Monitor" donde aparece una representación gráfica del uso de CPU total, del núcleo más cargado (el que tenga un uso mayor en procentaje), la frecuencia actual y el uso de memoria.
Se ha arreglado el botón de mostrar más información de la CPU. Ahora, al hacer clic, se muestra en el navegador la ficha del procesador.
También se ha encontrado una limitación artificial que impide detectar más 96 hilos, lo cual explica algunos resultado de CPUs monstruosas que han enviado y donde se veía este límite. Esto de momento está sin solucionar.
La descarga está disponible aquí.
Con esta versión, podéis validar resultados como si fuera la versión estable actual.
@jordiqui Veo que le das mucha importancia a la RAM pero el Ryzen 9 9950X3D tiene 128MB de caché de nivel 3 y 1MB de nivel 2. No sé cuanto consume SuperPi 32M, pero si se sale de los 128MB no será por demasiado. ¿De verdad afecta tanto la RAM? Y si afecta, al ser por cantidades pequeñas y un proceso intensivo de CPU, ¿no sería conveniente apretar las latencias más que la frecuencia? Es más, ¿no sería interesante probar a hacer underclocking a la memora con tal de mejorar las latencias?
Te lo comento porque yo estoy en el extremo contrario con los LLM con consumos enormes de RAM donde el ancho de banda es el cuello de botella predominante y donde tener mucha caché ayuda en cierta medida. Si por mi fuera, sacrificaría las latencias por ancho de banda porque sé que el aumento de rendimiento va a ser prácticamente lineal con cada MT/s que raspe.
Ya se ha descubierto la causa de las caídas del foro: un módulo de RAM defectuoso. Esta es de esas cosas que me ponen los huevos de corbata, pero dentro de lo malo, se trata de un módulo de 8GB DDR3, por lo que la crisis de memorias creo que afecta poco aquí (al menos no veo precios disparatados).
Estoy buscando uno de exactamente el mismo modelo y mientras tanto, se han redistribuido los servicios como buenamente se ha podido. Hasta que se sustiya, intentaremos sobrevivir con los 104GB de RAM que quedan operativos (y que dicho sea de paso, están prácticamente al 100%).
Sobre esto, estoy monitorizando la máquina de cerca por si no fuera sólo ese módulo o el problema fuera otro (placa base, zócalo, controladora de memoria o lo que sea).
Se sigue refactorizando el código. Si no hay demasiados contratiempos, en una o dos semanas saldrá la primera beta con alguna pequeña característica nueva.
Está bastante abandonada en general. Me he focalizado en nuevas características (federación del foro, becario agéntico con resúmenes de videos, el fallo de RAM que me ha tomado bastante tiempo, etc). Creo que es más interesante dedicar el tiempo a estas cosas que a la portada, así que en el medio plazo, habrá pocas entradas a la semana.
Como ya comenté, está federado y se puede intercambiar contenido con la instancia de Peertube. Os animo a que visitéis los hilos con los vídeos seleccionados. Hay uno sobre entornos de escritorio ligeros y otro de novedades de videojuegos donde se exponen los temas de una forma rigurosa y bien explicada.
Sobre la relación con los hilos federados, ya han implementado también el que aparezcan en hilos recientes. Esto hará que el contenido se traduzca (en este momento esos hilos están en un limbo). Pero no queda claro si saldrán en hilos no leídos cuando haya posts nuevos (incluso si son locales). El tema parece que no es filosófica ni técnicamente fácil de resolver.
Los ataques continúan por ráfagas, pero han bajando el ritmo. Las optimizaciones han llegado al punto de que el cuello de botella ahora es el ancho de banda (>400Mbps sirviendo sólo a scalpers). Buscaré la forma de minimizarlo sin afectar a otras cosas en la medida de lo posible.
Además, como algunos sabréis, se han descubierto varios fallos de seguridad importantes tanto en el kernel de Linux como en otros componentes. Aquí estamos al día pero en los últimos tiempos se están viendo cosas que no se veían antes y como dije en otra actualización, hay que estar muy al loro.
Un analisis interesante y es algo en lo que no había pensado. Yo aquí añadiría un par de detalles:
Por una parte, los entornos de escritorio consumían una gran cantidad de recursos en términos relativos desde mediados de los 90s a principios de los 2010s. Tenemos ejemplos en todos los ámbitos: desde el desastre del lanzamiento de Windows Vista en equipos nuevos de bajo rendimiento hasta un uso muy por encima de la media de KDE 4. O si nos vamos más atrás, el aumento de uso de recursos de DOS/Win3.11 a Windows 95 o de Windows 9x a Windows XP fue brutal. El cambio de Gnome 2 a 3 también supuso un antes y un después. Pero eso hace mucho que no sucede.
Con el tiempo, los entornos han ido consumiendo cada vez menos en términos relativos. Ya no hay grandes avances en este aspecto sino pequeños cambios mientras que el hardware sí ha ido mejorando durante todos estos años.
Básicamente, el mundo de los entornos de escritorio ha llegado a su zenit de consumo.
A día de hoy, Plasma es un entorno relativamente ligero y usar uno realmente ligero supone un ahorro de un porcentaje pequeño que ha dejado de merecer la pena.
El otro detalle es cuando comentas que 8GB es gama baja y 16 es media/productividad. Eso puede que fuera así hace un año. Con los precios actuales de la RAM, esa clasificación ha cambiado por completo y aquí los desarrolladores de software se van a ver obligados a invertir mucho en optimización si quieren vender sus desarrollos a un público mayor.
Pero como digo, los entornos de escritorio se han convertido en un componente que por mucho que se quiera, no va a ser un gran consumidor de recursos.
Desde hace unos días el foro forma parte del fediverso. Con esta nueva funcionalidad, estrenamos la primera pieza de la integración del foro con Peertube.
A partir de ahora, veréis en el foro hilos con un resumen de algunos videos seleccionados de la instancia de Peertube. Podéis responder a ese hilo y esas respuestas aparecerán automáticamente en el video de Peertube y viceversa, de forma que os podéis comunicar con los usuarios de la plataforma desde el foro.
Lamentablemente, NodeBB está un poco verde en este aspecto y, de hecho, esta capacidad de intercambiar mensajes es algo que pedí expresamente a los desarrolladores y que, amablemente, han implementado en la última versión.
De momento, los hilos federados no aparecen ni en la lista de hilos recientes ni no leídos. Además, el primer post del hilo sólo muestra la descripción pero no el video. Esta integración ya está pedida y lo de mostrar el video en el primer post del hilo es algo que ya han implementado y saldrá en la siguiente versión. Lo de tratar hilos federados como hilos normales parece que va a tardar más.
Mientras tanto, para dar visibilidad a esos hilos y que podáis participar desde el foro si os interesa el tema, en este mismo hilo, nuestro estimado becario @HIAL-9000 irá publicando un post con el video y un enlace al hilo del foro en el que podéis participar. Tened en cuenta que desde que aparece el hilo en el foro hasta que se muestra el resumen del video, pasan unos minutos.
Se trata de una característica experimental, se están haciendo pruebas de estilo para que los textos queden bien como fuente de debate/comentarios y no hay un criterio definido para la selección de videos.
Buenas @jordiqui. Lo más sencillo sería ponerlo sobre un fondo de color plano, que en este caso sería el fondo negro del chat. Como lo tienes ahora no queda del todo mal, pero los colores corporativos no dejan mucho contraste con fondos oscuros.
Aquí te dejo una propuesta de logo adaptado a fondos oscuros (esquema similar al programa del banco de pruebas) en que el he aumentado un poco el tamaño dentro del chat: